
クローリング・スクレーピングのフレームワーク「Scrapy」(スクラッピー)についてまとめます。
Scrapyとは
Scrapy(スクラッピー)とはPythonのクローシング・スクレイピングをするためのフレームワークです。
用語を補足すると、フレームワークとはシステム開発を楽に行えるように用意されたプログラムのひな形のことです。
クローリングとはWEBサイトを巡回し、HTMLをダウンロードする行為です。
スクレイピングとはダウンロードしたHTMLを解析し特定の文字列を抽出する行為です。
クローリング・スクレイピングによって、WEBサイトに自分でアクセスせずに機械に自動的にWEBサイトを巡回させて大量の情報を自動収集させることができます。
活用の一例としては、定期的に複数のサイトの商品と価格一覧を取得して、最安値を教えてくれるシステムとか。値段に動きがあったり、新着商品が追加されたら通知させるといったシステムを自前で構築出来することが出来ます。
Scrapyを使うメリット・デメリット
クローリング・スクレイピングはScrapyのようなフレームワークを使わなくても出来るには出来ます。
Linux系OSのダウンローダーWgetを使ったり、Pythonの標準ライブラリurllib.requestモジュール使えば、クローリング(Webページ取得)が出来ます。
スクレイピングにおいても、Beautiful Soupといったモジュールを使って実現できます。
ではなぜScrapyを使うのかというと、その理由は中〜大規模なクローリング・スクレイピングのシステムを実装する上での、トラブルシューティングのし易さと、コーディングのし易さにあります。
中〜大規模である理由として、クローリングの規模が大きくなると自前のクローリングシステムのメモリや回線帯域だけでなく、ターゲットとなるサイトのサーバーリソースの状況や帯域、障害等もクローリングの成否に関係するため一部データ取得を欠損したり、丸ごと失敗すること多々あります。
失敗の原因を突き止めるためには、ログ調査が必要となり、Scrapyにはその調査に必要なログ排出の仕組みが既にプログラムに組み込まれているのです。
この仕組みを自分で一から作るとなるとかなり大変な作業になります。
特定のWEBサイト1ページのみ定期的にクローリング・スクレイピングするのであれば、失敗は少なく仮に失敗したとしても原因特定し易いので、フレームワークを使う必要はないでしょう。
また、コーディングのし易さについてですが、フレームワークというのは既に基本的なプログラム、つまり誰が作ってもここの共通する機能が組み込まれてます。
例えば、以下の図がScrapyのアーキテクチャですが、この流れはすでに出来上がっており、利用者はターゲットのサイト情報や抽出するHTMLの箇所、DBへの保管方法といった最低限のコーディングをするだけでよいのです。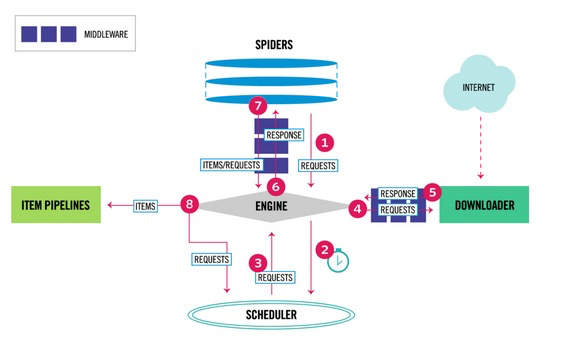
一方でフレームワークのデメリットは学習コストにあり、上記アーキテクチャーの細部について学習する必要があります。
ただ、最初のフレームワークの仕組み理解への学習コストを払えば、そこから先は楽できるので、Scrapyを使うべきかどうかの判断は「あなたが何をしたいのか」次第になります。
ScrapyとRPAの使い分け
情報の取得という観点だと、フレームワークの使うかどうかという話とは別に、RPA(ロボティック・プロセス・オートメーション)を使うべきかどうかという検討もされるかと思います。
RPAを使えば、定期的に夜寝てる間に勝手に複数サイトから情報取得することも出来ます。
取得する情報量、特定サイト数ページであればRPAでもいいですが、数百ページとなるとScrapyがよいでしょう。
RPAを動かしている間はPCが使えないのと(サーバーサイドで動かせば関係ないですが)、所詮はGUIのオートメーションなので数ページ取得するのに数分かかってしまいます。
また、DB連携とかすると、GUI→CLIへの連携も必要となり変換が面倒です。
一方、Scrapyであれば数百ページの取得が数十秒で出来てしまいます。
なお、自動化を実現するためのRPAツールを使うのがいいのか、iPaaSのサービスを利用するのがいいのか、Scarpyといったフレームワークを使った独自開発がいいのかといった比較についてはこちらに記載してます。

Scrapyの使い方
ここからはScrapyの使い方について解説します。
scrapyのインストール
インストールについては環境によって異なるので本家のサイトを参照ください。
scrapy startprojectによるプロジェクトフォルダの作成
まず最初に新規プロジェクトを作成します。以下コマンドを入力するとカレントディレクトリにプロジェクトフォルダが作成されます。
scrapy startproject プロジェクト名buppanprojectという名前で新規プロジェクトを作成すると、カレントディレクトリに以下のファイルが自動的に作成されます。
scrapy genspiderによるスパイダーの作成
次に新規スパイダーを作成します。スパイダーとはクローリング・スクレイピングのプログラム本体です。
以下コマンドを入力するとspidersフォルダの中に作成されます。
(URLは最初は適当でいいです。コマンドはbuppanprojectフォルダに移動してから入力してください。)
scrapy genspider スパイダー名 URLbuppanという名前でスパイダーを作成すると、spidersフォルダの中にbuppan.pyというファイルが自動的に作成されます。
Javascriptを無効にしても取得したい情報が表示されるか調査
次にターゲットとなるサイトがJavascriptを使って表示されているかどうかを調べます。
ブラウザがFirefoxの場合は以下手順で調べられます。
1. アドレスバーに「about:config」 と入力
2. 検索窓に「javascript」 と入力
3. 「javascript.enabled」という項目を探す
4. この項目をダブルクリックして Valueをtrueからfalseを切り替える
Javascriptを無効にしても取得したい情報が表示される場合、通常手順で取得可能です。次の手順に進みます。
(逆に取得したい情報が表示されない場合は、レンダリングサーバーを用意する必要があり若干追加の手順が必要となります。別途記事作成予定。。)
各種設定ファイル(items.py、pipelines.py、setting.py)を修正
次にスパイダー以外のファイルを修正します。修正するファイルは基本的には3ファイルだけでよいです。
それぞれの役割は以下の通りです。
・item.py :DBに格納するカラムを定義する
・pipelines.py :DBのテーブル作成やデータの更新、画像の保存処理を定義する
・setting.py :エンコーディングやページのダウンロード間隔といった基本設定
scrapy shellによるインタラクティブなスクレイピング
次にインタラクティブなスクレイピングをしながら、ターゲットとなる情報を取得可能なスクリプト調査をします。
以下コマンドを入力するとインタラクティブなスクレイピングを開始出来ます。
scrapy shell URL書き方のパターンは以下の通りです。
見出しからURL一覧を取得し、URLから次々と記事をダウンロード。(クローリング)
書き方その1:特定classからhrefを抽出
>>> response.css(‘.class名 ::attr(“href”)’).get()
書き方その2:LinkExtractorを利用
rules = (Rule(LinkExtractor(ドメインの後のディレクトリ名), callback=’parse_topics’, follow=True),) *follow=Trueはリンク先に更にリンクがあった場合辿る
書き方その3:sitemapspider(XMLサイトマップ)を利用
ダウンロードした記事からタイトルと本文を取得(スクレイピング)
書き方その1:特定classから抽出
>>> response.css(‘ .class名‘).xpath(‘string()’).get()
書き方その2:readability-lxmlを利用(不特定多数のサイトから抽出する場合に利用)
scrapy crawlによるスクリプトの実行
最後に作成したスクリプトを実行しターゲットとなる情報を取得していきます。
以下コマンドを入力するとクローリング・スクレイピング・DB保存等を開始出来ます。
(コマンドはbuppanprojectフォルダに移動してから入力してください。)
scrapy crawl スパイダー名以上、Scrapyに関する解説でした。

